Styrkan i Regular Expressions och Google Analytics

Det finns otroligt mycket man kan göra med Google Analytics, trots att det faktiskt är gratis (i de flesta fall, och för de som behöver betala är det orimligt billigt hur som helst). Men för att utnyttja Analytics fullt ut borde man fördjupa sig i Regular Expressions, eller reguljära uttryck. Det kan i väldigt många fall hjälpa dig när du vill göra avancerade filter, sätta upp målspårning eller segmentera trafik. Men för att kunna skapa dessa är en av förutsättningarna att man förstår sig på grunderna i Regular Expression, det är i sig en hel vetenskap men genom att prova sig fram kan man skapa otroliga saker.
Innehåll
Backslash –
Pipe – |
Frågetecknet – ?
Parentesen – ()
Punkten – .
Brackets, sträck och klammer – [-]{x,y}
Stjärnan – *
Backslash –
Vi börjar med backslash eftersom det antagligen är den du kommer använda mest och den du kommer behöva mest. Backslash kommer användas i de fall när vi vill göra regular expression till vanlig text. Dvs. om vi har en URL som innehåller ”?” har vi ett problem eftersom ”?” också fyller en funktion för regular expression. Genom att då använda oss utav kan vi ta bort funktionen för ”?”. Det kallas att escape:a tecknet.
Exempel:
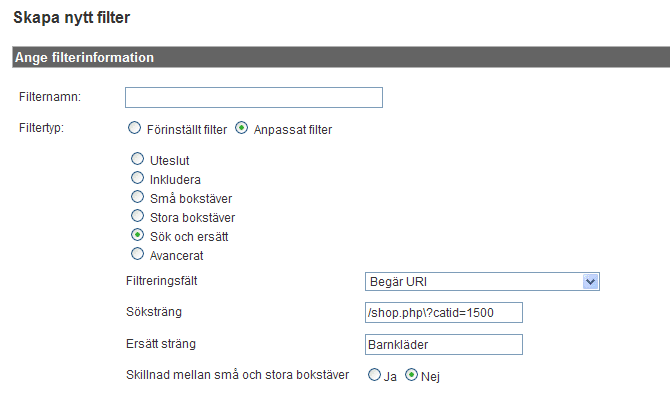
Regular Expression – backslash
Säg att vi har en webbshop som använder sig utav olika ID-nummer i URL:erna för kategorierna på webbplasen. Då kan vi med filtertypen ”Search and replace” (Sök och ersätt) skapa tydligare rapporter för personer som inte är insatta i webbplatsens URL-struktur. Men ett problem uppstår när vi skapar filtret eftersom URL:en innehåller ”?”. Genom att då sätta en innan ”?” tar vi bort funktionen för ”?”.
Pipe – |
Pipe, streck alt. eller-tecknet. Kalla det vad ni vill men den är väldig enkel och de flesta är nog väl insatta i vad den gör och hur den fungerar. Man använder | de gånger man vill använda sig utav funktionen ”eller”. I många fall kan det vara användbart när vi vill kolla på sökord folk har hittat till webbplatsen med.
Exempel:

Säg att vi skulle vilja jämföra två olika typer av besökare för att se vilka som konverterar bäst. Kanske vill vi jämföra de som hittar till webbplatsen med sökord som gratis och billigt med all övrig söktrafik. Då skulle vi kunna skapa ett avancerat segment där vi använder oss utav aspekten sökord och som innhehåller ”gratis|billig”.
Frågetecknet – ?
Som jag nämnde förut så fyller frågetecknet en funktion i regular expression. Vad den gör är att den markerar ett tecken eller uttryck som ”frivilligt”. Säg att vi i sökordsrapporten t ex vill filtrera ut företagsnamnet. Ditt företag heter Dansgruppen, men en vanlig felstavning är Dannsgruppen med två n. Då skulle vi istället för att använda oss utav eller-tecknet kunna skriva ”Dann?sgruppen” På så sätt filterar vi ut både Dansgruppen och Dannsgruppen, eftersom det sista n:et är markerat som frivilligt, det sista n:et behöver alltså finnas där.
Parentesen – ()
Fungerar med regular expression precis som det gör med matten. Om det faller inom ramen för ”saker jag borde ha lärt mig men jag aldrig gjorde”, var lugn, vi skall ta några exempel. Om vi tar fram våra gamla anteckningar från matten så kan vi förhoppningsvis hitta något liknande det här,
7+3*3 =16 – dvs. tre gånger tre är nio, sju plus nio är lika med sexton.
(7+3)*3=30 – dvs. sju plus tre är tio, tio gånger tre är lika med trettio.
Ni kanske kommer ihåg hur er mattelärare alltid sade, ”gånger först”. Men genom att använda oss utav parentes kan vi ändra i ordningsföljden hur man räknar ut ett tal. På ett liknande sätt kan vi använda oss utav parentes ihop med regular expression. Istället för matte så har vi ett likanade exempel med regular expression.
/mapp-ett|tva/kontakt = /mapp-ett eller tva/kontakt
/mapp-(ett|tva)/kontakt = /mapp-ett/kontakt eller /mapp-tva/kontakt
Vi kan alltså med hjälp utav parentes gruppera ett uttryck utan att det påverkar hela strängen i sig.
Exempel:
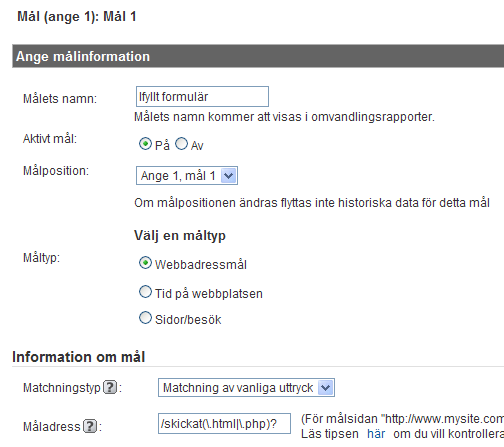
Säg att vi har en webbplats med olika formulär utspritt över hela webbplatsen och värdet/informationen per ifyllt formulär är det samma så vi vill samla alla dessa under samma målspårning. Problemet är dock att formulärerna använder sig utav olika slutdestinationer. Några kommer landa på /skickat några på /skickat.html och några på /skickat.php. Då skulle vi som måladress istället kunna ange /skickat(.html|.php)?
På så sätt täcker vi upp samtliga tre slutdestinationer, detta då frågetecknet gör vår parentes ”frivillig”, skulle vi ta bort frågetecknet skulle vi inte få med /skickat utan endast /skickat.html och /skickat.php.
Punkten – .
Som ni kanske såg i föregående exempel så använde vi oss utav backslash innan punkterna i filtret vi skapade. Med andra ord fyller alltså tecknet . en funktion i Regular Expression. Vad punkten gör är att den matchar med vilket tecken som helst. Så egentligen skulle vi inte behövs använda oss utav backslash innan eftersom vi troligen inte kommer råka ut för något annat än just en punkt där. Den används kanske inte så ofta men kan vara väldigt användbar ihop med andra uttryck.
Da.is – kommer matcha, Dagis, Da.is, Da_is etc etc. Men inte Dais.
Exempel:
Säg att vi vill filtrera ut trafik från en viss ip-range. Om ditt företag skulle sitta på alla ip-adresser mellan 83.75.140.250 till 83.75.140.255. Så skulle vi med regular expression kunna skriva 83.75.140.25. På så sätt täcker vi alla ip-nummer. Visserligen täcker vi även 83.75.140.256 med, men detta kommer aldrig hända eftersom det inte är ett korrekt IP-nummer.
Brackets (hakparentes), sträck och klammer – [-]{x,y}
Brackets används oftast ihop med ”-” och även ganska ofta ihop med klammer men går även att använda utan. Vi skulle för exempelvis i en sökordslista kunna använda oss av filter som [abc] då kommer vi se alla sökord som innehåller a, b, eller c. Skulle vi däremot skriva 1[abc]2 skulle vi endast se 1a2, 1b2 eller 1c2. Men bäst användning utav brackets har man som sagt ihop med ”-”. Då vi kan använda oss utav följande tekniker,
[a-ö] – Alla gemener mellan a till ö
[A-Ö] – Alla versaler mellan A till Ö
[0-9] – All siffror mellan noll till nio
[a-öA-Ö0-9] – Alla samtliga ovan (notera att man inte använder sig utav pipe eller något kommatecken.)
Än fräckare blir det när man börjar använda sig utav klammer. Om vi tar exemplet ovan igen fast lägger till en klammer så vi får 1[abc]{1,2}2. Så kommer vi nu utöver dem i första exemplet även matcha 1ab2, 1ac2, 1ba2, 1bc2 etc etc.
Klammer fungerar alltså på det sättet att man repeterar föregående uttryck mellan X till Y gånger.
Stjärnan – *
Stjärna är kanske det tecken som inom regular expressions oftast används felaktigt eftersom den inte riktigt har samma funktion som den annars brukar ha. Stjärnan betyder att man tar förgående tecken och repeterar det mellan noll till otaliga gånger. Så Bä*st kommer alltså matcha både Bäääääst och Bst. Stjärnan i sig är kanske inte så användbar, men ihop med punkten kan vi skapa fräna saker. Ett filter som jag ofta använder är ett filter som gör det möjligt att se hela url-adressen vår besökare kom ifrån.
Exempel:
Om vi skapar ett filter enligt följande inställningar.
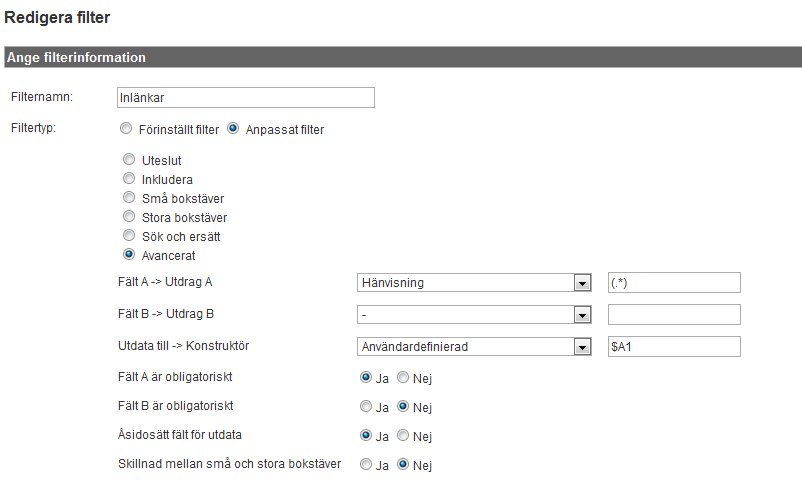
Filtertyp: Anpassat filter = Avancerat
Fält A -> Utdrag A: Hänvsining = (.*)
Fält B -> Utdrag B: lämna tomt
Utdata till -> Konstruktör: Användardefinierad = $A1
Fält A är obligatoriskt: Ja
Fält B är obligatoriskt: Nej
Åsidosätt fält för utdata: Ja
Skillnad mellan små och stora bokstäver: Nej
Så kommer vi med det här filtret kommer vi alltså kunna se ifrån vilken URL-adressen besökaren hittade till vår webbplats med. Rapporten kommer vi sedan hitta under Besökare -> Användardefinierad. Tänkt på att filtret först börja fungera från det att du skapade det.
Förhoppningsvis har du nu lärt dig lite mer om Regular Expressions och hur du kan använda det ihop med Google Analytics. Längre fram kommer vi bottna ner oss än mer i Regular Expressions, men till dess låter jag er testa er fram med materialet ni hittar här. Lämna gärna en kommentar om hur du vill kunna använda eller hur du använder det med Google Analytics idag.